


By Walt Hickey
Welcome to another Numlock Sunday podcast edition!
This week, I spoke to Surya Mattu and Aaron Sankin, who wrote Crime Prediction Software Promised to Be Free of Biases. New Data Shows It Perpetuates Them for The Markup. Here's what I wrote about it:
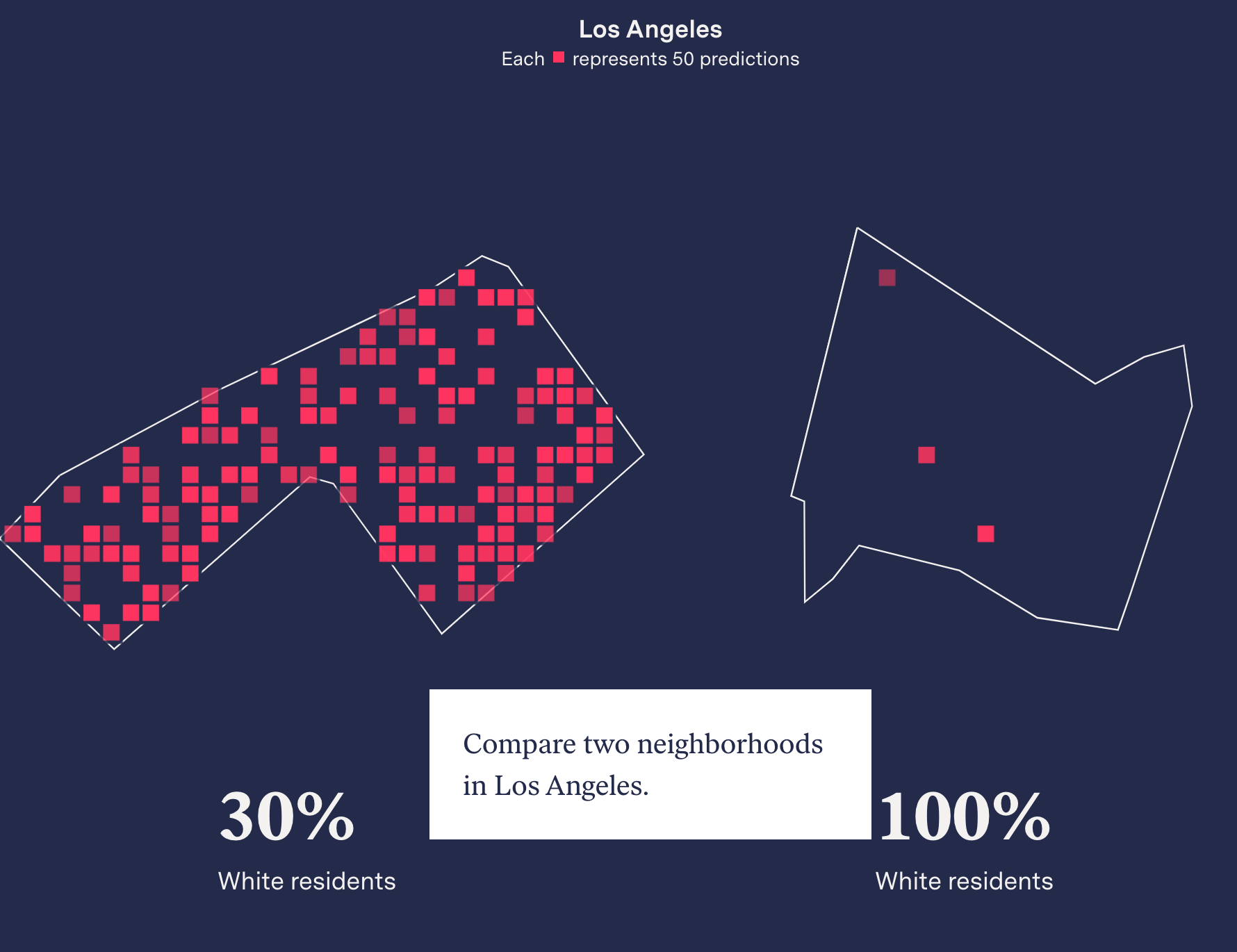
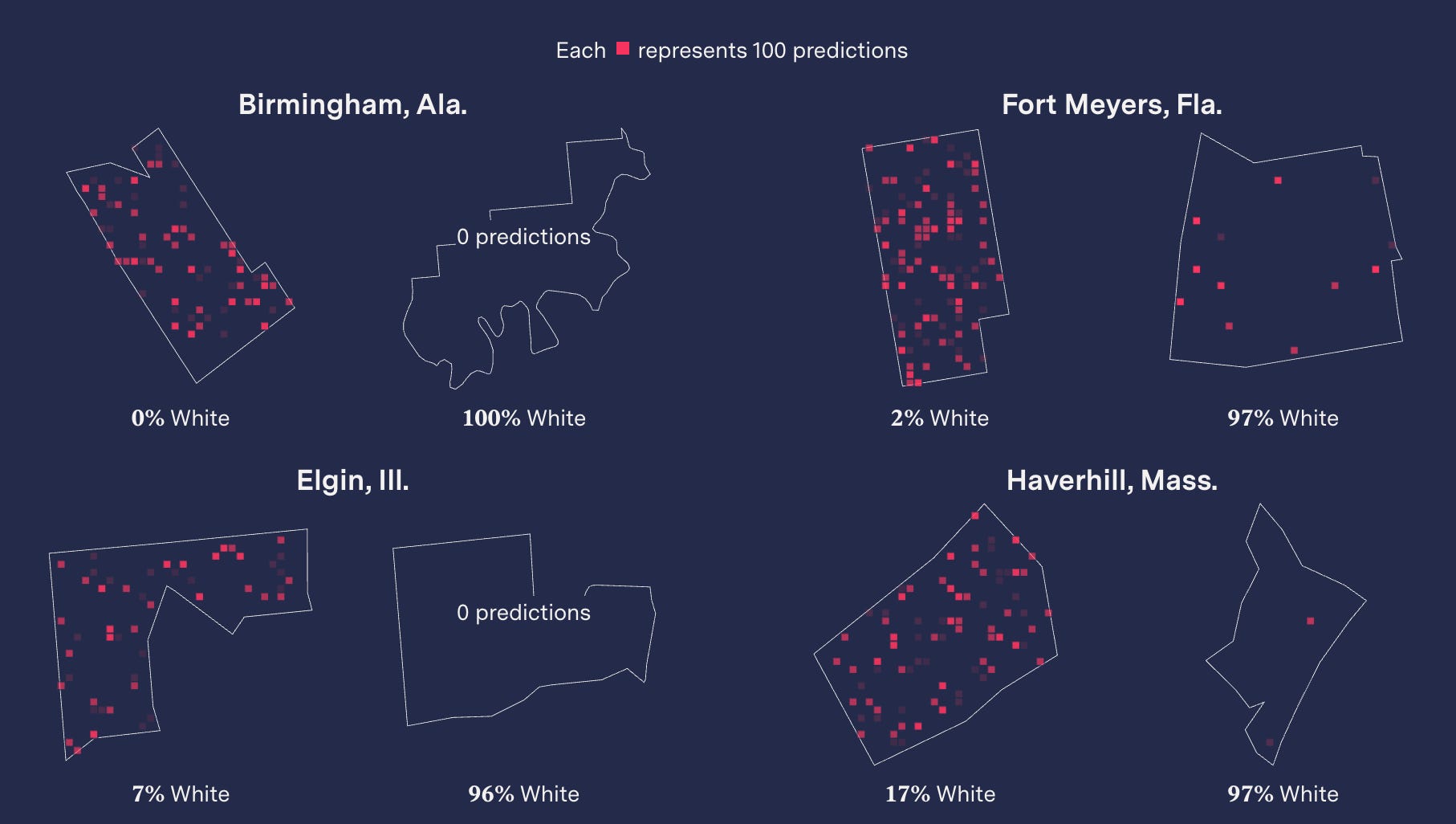
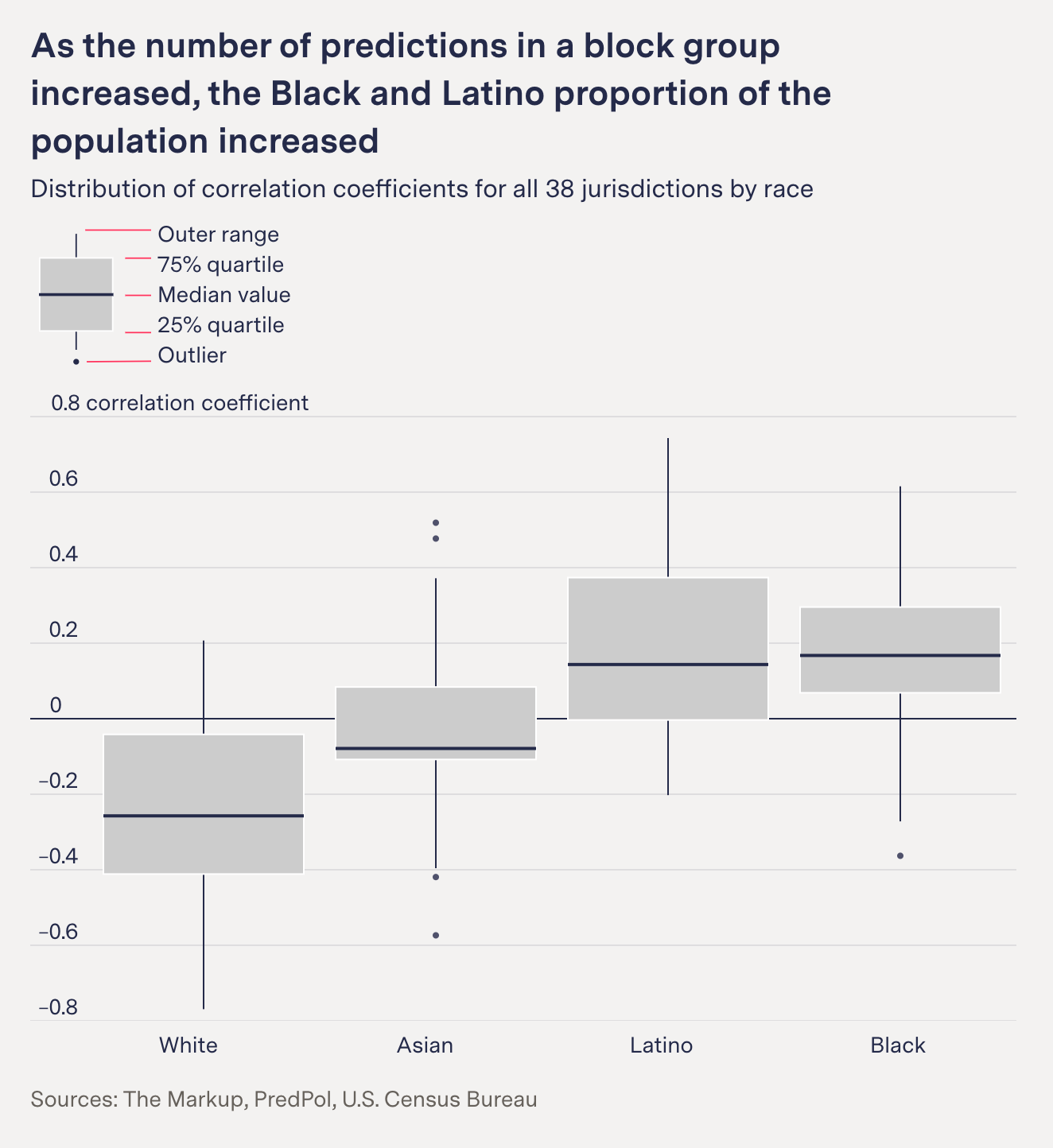
An analysis of 5.9 million crime predictions from a company called PredPol — predictions that informed policing in multiple cities across the country, affecting something like one out of every 33 Americans from 2018 to 2021 — found that the recommendations appear to be lousy with racial bias, persistently recommending increased patrols in neighborhoods with higher percentages of Black and Latino residents, with some neighborhoods seeing multiple crime predictions per day. Even when crime predictions targeted a majority-White neighborhood in the Northridge area of Los Angeles, it clustered those forecasts on the Latino blocks. The most-targeted neighborhoods were 28 percent more Black, 16 percent more Latino, and 17 percent less White than the overall jurisdiction. The efficacy of these programs is suspect, as there’s no vetting if the predictions actually bear out, or any report when a crime prediction software leads to charges. Critics allege the software is little more than “bias by proxy,” offering a justification to over-police certain areas with a vague algorithmic justification.
This is an incredibly well-reported story, and shines a light on how software that attempts to predict crime can unintentionally come bundled with a bunch of racial biases.
We talked about how exactly they managed to report this out and how The Markup is able to use data to bring accountability to new technology that hasn’t been adequately vetted.
Mattu and Sankin can each be found on Twitter, there’s a bunch of data for this story they’ve uploaded to GitHub if you’re interested in getting hands on with it, you can read more about how they pulled this off here, and the story is over at The Markup.
This interview has been condensed and edited.
You two wrote a really fantastic story over at The Markup, you're both data reporters over there so you were really in the weeds on this one. It's all about crime prediction software, and some of the issues inherent therein. Can y'all tell me a little bit about crime prediction in general? Are police offices really using software to try to predict crimes before they happen?
Aaron Sankin: Our story was looking at a particular piece of crime prediction software called PredPol. And the way that PredPol works is that it ingests crime report data, which is information that comes from if someone calls an 911 saying, "My car was broken into." Or if a police officer is driving around and they see someone in the act of breaking into a car and arrest them. So all of that crime report data then gets fed into an algorithm that is inside of this system that was devised by PredPol. And from there, it points on a map the locations where and when they think that crime of this particular type is most likely to happen.
And then from there, the idea is that you can direct an officer while on patrol to go to that area, and either by their sheer presence will dissuade criminals from offending in that area, or they will catch them in the act. And that is effectively how this system that we looked at works. There are other predictive policing systems that are more person-based, looking at who might either commit a crime or become a victim of a crime. But the things that we were looking at are very tightly focused on this kind of location-based type of prediction.
Y'all obtained just a wild set of data, something like 5.9 million crime predictions. What was it like to work with that? And what format did they come in? Like, how'd you even embark on this?
Surya Mattu: We had 5.9 million predictions that we used for this analysis. But actually the data that our colleague on the story, Dhruv Mehrotra, found on the internet was more than that. It was actually around 8 million predictions across 70 different jurisdictions, including some really interesting ones. Like I found some data from Venezuela and Bahrain, which didn't make it into the story, but that was what he found. All of that data, by the way, is on the GitHub repository that goes with this, there's a link in our methodology to the data if anyone wants to play with it. The raw data itself came to us in the form of HTML files, it was about, I forget how many gigabytes, but many, many gigabytes of just raw HTML that we then had to parse and write parsers to convert into spreadsheets that we could then use for analysis.
Just kind of taking a step back to the final story in which you ended up finding, algorithms are oftentimes sold as impartial ways to understand the world, but your report really found that that's not the case at all. That the human biases of the people who design the algorithms kind of make it into the final data. Do you want to talk a little bit about what you found?
Surya Mattu: What we basically found was that across 38 jurisdictions that we looked at, the software disproportionately targeted low-income Black and Latino neighborhoods. And we define proportionate here as compared to those jurisdictions overall. That obviously comes with caveats, such as crime isn't spread equally across a place. It happens at specific locations and all of that. But what we found was that this underlying trend did exist in the data we had.
The reason it was important, we thought, to do this analysis and present it this way is because as you said, we wanted to just prove definitively that with real world data, people can't say that algorithms aren't racist because they're not looking at certain types of data such as demographics. The point we were trying to make is that that will be reflected in the outcome of software, even if you don't include it, because as you said earlier, the systemic bias is kind of embedded within the input data that's going into these algorithms.
Aaron Sankin: I think that's a really important point that Surya makes about the issues around the input data. Because PredPol's algorithm, because the founders of the company are academics, they had disclosed previously just the core of their algorithm in an academic paper that they published a number of years ago. The inputs to this do not specifically mention race, they don't mention income. The inputs to the system are just the crime reports. And what they take away from a crime report is really just the type of crime, the time it happened and the location. And that's it. The issue here is essentially, what is creating this kind of disproportionate skew targeting these certain neighborhoods?
It is based around, what is going in, what inputs are coming into those crime reports. We can talk a little bit about the issues of input data affecting an algorithm, but you have things like fundamentally different rates of crime victimization in different neighborhoods. You have issues around, as you know, the Bureau of Justice Statistics has found repeatedly that Black and Latino and low-income people tend to report crimes at higher rates than white and higher-income people. And also issues around feedback loops, where if there are officers in a particular area, they're more likely to see crimes in the areas where they patrol.
And then because of that, they see those crimes, they identify the crimes and then the crime report data then comes back from that, comes back into the system. There's a lot of different things that are all working together here. But I think it's also important to say that, all of this stuff can happen in systems that are facially neutral about this.
I think a big takeaway for this story for me is that this system, PredPol, is intended to take away the opportunity to have individual biases of a police officer affect where they patrol. You could say, yes, you're concerned about individual police officers saying, "I want to patrol the Black neighborhood or Latino neighborhood. And that's where I'm going to spend all my time." And this system is intended to kind of circumvent that in a lot of ways. But at the same time, because the input data is what it is, you're then going to get potentially very similar results to if you just had a police officer going on their own kind of biases and history and common sense and experience.
That feedback loop seems like a big problem. Because again, if it's designed to subvert the desire to over-police different areas, but it's based on the fact that people are already over-policing specific areas, that seems like it's kind of a key issue here.
Aaron Sankin: Yeah. A kind of caveat here, and Surya can go into this because he did a lot of this data work, is that fundamentally what we were looking at is the algorithm, right? We were looking at these inputs and outputs because it was really difficult for us to get a handle on how this was being used by individual police departments, right? That was a question that we asked to all of these departments that were in analysis, we're like, "How did you use it?" And we had a lot of variance. Some departments were like, "Yeah, we use it all the time." And other departments were like, "We hardly use this at all, even though we're paying for it."
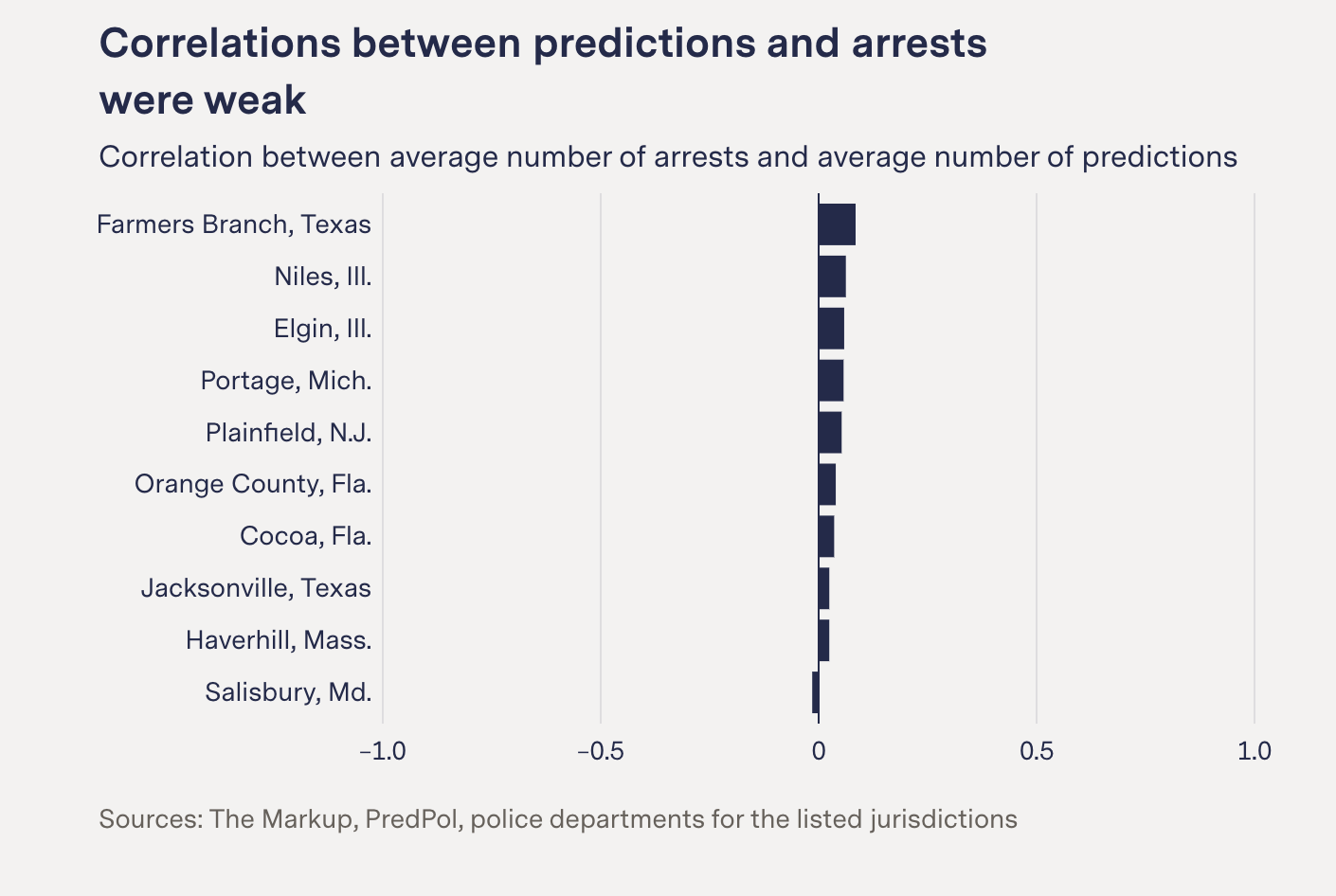
But at the same time, we had specifically asked all of the police departments, "Had this system directly led to arrests? Can you recall any specific time where PredPol said, there was going to be a crime here, and then you went to that area and then you made an arrest?" And none of them responded to that in the affirmative. And whether that's because it wasn't particularly useful for that or because that information never made it into their system, which I think is a big issue with the system where information about whether or not a stop and arrest was a direct result of a prediction, is generally, from what I can understand, not making its way into kind of the legal system.
It's really hard for us to know exactly how this is being used. I think therefore, it also makes it a little fuzzier in terms of the feedback loop question. Because that was a concern that I think a lot of activists and critics and academics who have been studying and raising the alarm about place-based predictive policing systems, like PredPol, have worried about. And I think that was something that we wanted to be able to answer, but because we weren't able to get a lot of clarity on that, we can't say with any certainty exactly how big that feedback loop issue is, even though it's certainly there.
Surya Mattu: Right. Just to add to that, in the data, that's why we went with this disparate impact analysis at the end. Because really what we're measuring is where these predictions took place and kind of who lives there, right? Because that's the one thing we could be really specific about and measured precisely. All of the stuff Aaron just said, I think, is a good explanation of why we chose this analysis in the first place.

One thing I really enjoy about The Markup's coverage in general is that you do have the technical ability to look at these algorithms and understand what's going on here. It seems interesting that in this case, Aaron, to your point, that oftentimes algorithms will have a way to kind of train themselves for accuracy, that they would find results about how efficacious they actually are and try to get more like that. But it doesn't sound like that's happening here.
Surya Mattu: Well, that gets to a really kind of interesting thing we've seen both in the academic literature and just kind of through our own research as we've been working on this stuff is, the way I kind of joke about it is that you either look at systemic inequality as a feature or a bug of society.
Whoa.
Surya Mattu: Right? And I think that that's basically the two views. We look at it as a feature of society, right? So when we're doing our analysis we're saying, "We know this exists. Is it being reflected in this new system?" So the analysis we're doing is kind of treating systemic inequality as a feature. What PredPol, the company and the software they made, is doing is kind of treating it like a bug.
They're saying that, "Oh, this is a problem. If we don't look at it, it's probably not going to be there. It's not going to affect us because we're not looking at it. But it's not ours to fix. If it got fixed, the software would work, super perfect and super unbiased.” And then I think fundamentally, that's the different... Like that's the back and forth in this conversation. Does that make sense?
Yeah. What you're getting at here is that, you view the systemic inequality component as a fundamentally central feature of what the inputs are in this, either implicitly or not. Whereas if you're operating a police prediction algorithm, that's just like, "Well, that's not really our department." And as a result, pretending it doesn't exist, which, does that cause the issues that you're kind of realizing in this?
Surya Mattu: Yeah, exactly. Because, I mean, if you're PredPol, what do you do? Aaron can talk about this more, but he found a study in which they have looked into this issue themselves. They basically kind of came down to the fact that, "Yeah, it can perpetuate systemic biases, but we don't know what to do about that. We're just going to leave it because it also can make it ‘less accurate’ if you start trying to be less precise in where you target. Or look into these other features to determine whether people are being exposed to these predictions."
Aaron Sankin: I think something important here is, essentially, the way The Markup operates with these sorts of investigations is we'll do our analysis and we'll put together a whole methodology and then we'll send it out to the company or whoever we're investigating for an adversarial review. Just like, "Hey, what do you think about this whole method that we did?" And then we had a whole bunch of questions and stuff.
I think we asked pretty point-blank of like, "What do you make of these differences?" And, "This is who's getting targeted across all these jurisdictions." And their argument was really like, "We don't really have a problem with this because it's based on crime reports. These are the neighborhoods that legitimately need more policing." Again, it's like, if this is what the algorithm says, it's good because it's based on this data, it's not based on human biases. I feel like that's a question a little above my pay grade, in terms of what's going on and what is an appropriate level of policing in each of these communities.

Because in certain parts of these jurisdictions, I'm sure there are a lot of people who say, "Yes, I want more cops in my neighborhood." And then there are other people who are saying, "I think the policing levels here are too high." What I was really excited to do with this story is allow those conversations to happen locally, because they are not really ones that can happen at the national, 30,000-foot view. Even though there is research that shows there are problems that happen around over-policing and what happens to individuals and young people and communities when there are a lot of negative interactions with police.
But those decisions need to be made at the individual and local level. I think at least in my conversations with a lot of activists and leaders in a lot of these cities, they didn't know this was being used. They hadn't heard about this stuff before. It really just needs to be part of that conversation, to decide if it's something that needs to be appropriate or not. Because at the same time, there is research that does suggest that crime does coalesce into hotspots, and even just having a cop on a corner for a little bit of time can often decrease the levels of reported crime in a community.
There are lots of different trade-offs that are happening here. I just think in order for a community to really reckon with the levels and types of policing that it wants to have, they just need a certain degree of information. And I think that is what, in a lot of ways, what we're trying to do with this story.
Again, I love this story. It's so in-depth and folks should definitely check it out if they haven't read it already. But the thing that is really interesting about it is, I almost got the sense that describing it as a crime prediction software is kind of undermining what it's trying to do, in the sense that it seems like it's less a weather forecast and more a climate forecast, and misleading these two things is just kind of leading to disproportionate coverage. Again, you guys were really involved with the data. I would love your thoughts on that.
Aaron Sankin: I think I had heard it described as less about finding the location or the most likely location for future crimes, it's more about finding the location where someone will make a report about a crime in the future, if that makes sense. And those two things aren't necessarily the same. That's what's important to think about. What this is predicting is incidents of people or police officers reporting crime to authorities, which is different than people who are victimized by crime, if that makes sense.
Yeah, I get that. That does make sense. The work that y'all do at The Markup is so great, you have also covered things not just involving predictive policing. You've covered Facebook, you've covered Google, YouTube, all this kind of thing. In the course of covering the algorithms that you've covered, have you noticed any reliable blind spots that folks who are designing these kind of keep on running into?
Surya Mattu: One of the things we do in our analysis and our methodologies is we are always really explicit about the limitations of our analysis and what we can and can't say, and how we had to limit what we were looking at. And I think that is something that I wish I would see more in technology overall, is this more rigorous — the way I think about it is like, you know how you have penetration testing for security?
Sure.
Surya Mattu: Where people hire white hat hackers to come and test the security of their systems, because they can build it as well as they want but until someone is going to really find all the leaky pipes, you're not going to know. You need a similar kind of approach. The work we do really kind of comes down to a lot of data collection and cleaning. With this story, it's 5.9 million records, but we had to geocode each one of those lat-longs, connect it to census data, do over a hundred FOIA requests to join the data, to actually be able to even build the datasets we needed to do an analysis to answer a question.
I think that's the kind of work I hope in the future companies start doing more and more of around the products they're putting out into the world. There could be a variety of ways in which that happens. You could talk to advocates and experts and people who work with vulnerable communities who are the most likely to be harmed by these tools to see what it looks like on the ground. I don't see that happening as much as I would like it to. I'm hoping that the work we do at The Markup raises that conversation around what it looks like to do internal adversarial testing of how your technology influences society.
Aaron Sankin: That makes me think about a story that came out a few months ago. It was probably the thing this year that a tech company did that I just really appreciated the most. It was a report that came out of Twitter, and their report was basically that they had studied it and they found that basically everywhere that Twitter operates, it is amplifying right-wing content more than it is amplifying centrist or left-wing content. The key here is that they say, "We do not know why this is happening. We looked at this and this is a real thing. We have studied this. This is a systematic bias in our system, but we cannot figure out what is the core reason that this is happening across so many countries all over the world."
I thought that was just such an important way to do that in a couple ways. I think, one, because they are admitting there's this big gap in their knowledge. They're admitting that this thing is a process. But also, there's a certain degree of transparency in saying, "We are studying this and looking into it and we think it's important. And we would like to know more, but we're not quite there yet."
I think that is something that The Markup tries to embody as well in our work of saying, "These are the limits to our knowledge in terms of the research and analyses and reporting that we've done." I really like seeing that from a big tech company that deals in algorithms like that. It also made me think about how rare that sort of statement and sentiment is among kind of like Twitter's peers and big tech, algorithmic space.
That's really insightful. I love that observation that again, just for whatever reason, whether it's just the Silicon Valley culture, or even just like how people understand and reconcile the things that they've built with the impacts of the things that they've built. But there really is a lack of technological humility from a lot of different circles on this, that you guys very well illustrate in your own work.
Surya Mattu: I really like that term, technological humility. I'm definitely going to use it in the future.
Steal it. All yours.
Surya Mattu: That is what we're after here. One thing I always say at work is that, we're kind of like the Mr. Rogers of data, we want to be honest and treat you like the humans and who'll understand nuance and can understand a detailed, complicated thing. Where it's not like just finger pointing and saying, everything is bad. We're trying to show you that things are complicated. Here are the tradeoffs, here's what we can say, here's what we can't say.
I think if you can do that with nuance and specificity and really precisely define the problem, even if you can't solve it, it gives people a little more agency on how they want to deal and interact with it. And I think that's a big part of what our job is here. Is to just shine a light and give you the nuance and details so you can understand how to think about the system.
I love that. And again, so y'all at The Markup have been at this for a while. The reports that you come out with are really terrific. I suppose, like in this kind of specific case, there are a couple of stakeholders involved, right? There are these different municipalities in the cities. I guess, how has the reaction been and how do you kind of hope people use what you've found in their own municipal basis?
Aaron Sankin: I think it's still a little early to get a sense of the reaction post-publication. But really, one of the things that I found really interesting is, once we had conducted and finished and locked down our analysis, we went to all of the departments that were included in it. Surya had made these really great data sheets, which are available in our GitHub, that break down the targeting for each city. We provided these things to each of the departments and we asked them a whole bunch of questions about their own use of this system.
We got, I think, about like 15 or so departments to respond to us. Most of those were ones that had used this system at one point and then stopped. The thing that struck me was this kind of consistent refrain from a lot of departments that had used PredPol and then stopped, was that they were like, they felt that it wasn't telling them anything they didn't already know, which kind of makes a lot of sense.
Because a lot of these are smaller or mid-size cities. You have not a huge jurisdiction and you have police officers often who have been working in these beats for years, if not decades. They're like, "Yes, I know where to go, where there are the car break-ins. I know generally where the muggings happen because they are there in these communities." I think that struck me as something that was really interesting. Because it suggests, is this a really great purchase or product for these departments to be making at all?
But also at the same time, if we are finding that these predictions, which are based on the crime report data, are so closely lining up with the preconceived notions of the individual police officers, is this whole system just replicating or reinforcing the same sorts of biases that have already been in there that could end up being fairly problematic? I think that, to me, was something that I found particularly interesting in interfacing with all of these departments.
It makes me think also of, there's some really excellent work by a University of Texas sociologist named Sarah Brayne, and she had done work at the LAPD, looking at their uses of technologies. One of the insights that she had seen is that to her, it kind of like, in a sense, functions as almost a de-skilling of police work, where it's like, you have police officers who feel like they have all of this knowledge and suddenly they're taking directions on where to go from a computer. And it's like, we already kind of know this. So I thought that's something that was really interesting and interfacing of how this stuff is working on the ground, in that it didn't seem to be telling — at least any of the departments I had seen — anything that was particularly surprising to them.
One example is, there was a department. They were like, "Yes, we had a car break-in at an area where PredPol had made a car break-in location. But we already knew that there were a rash of cars that were getting broken into there. And the car that was broken into was a bait car that we had stuck there a while earlier. So, you can't credit it to that."
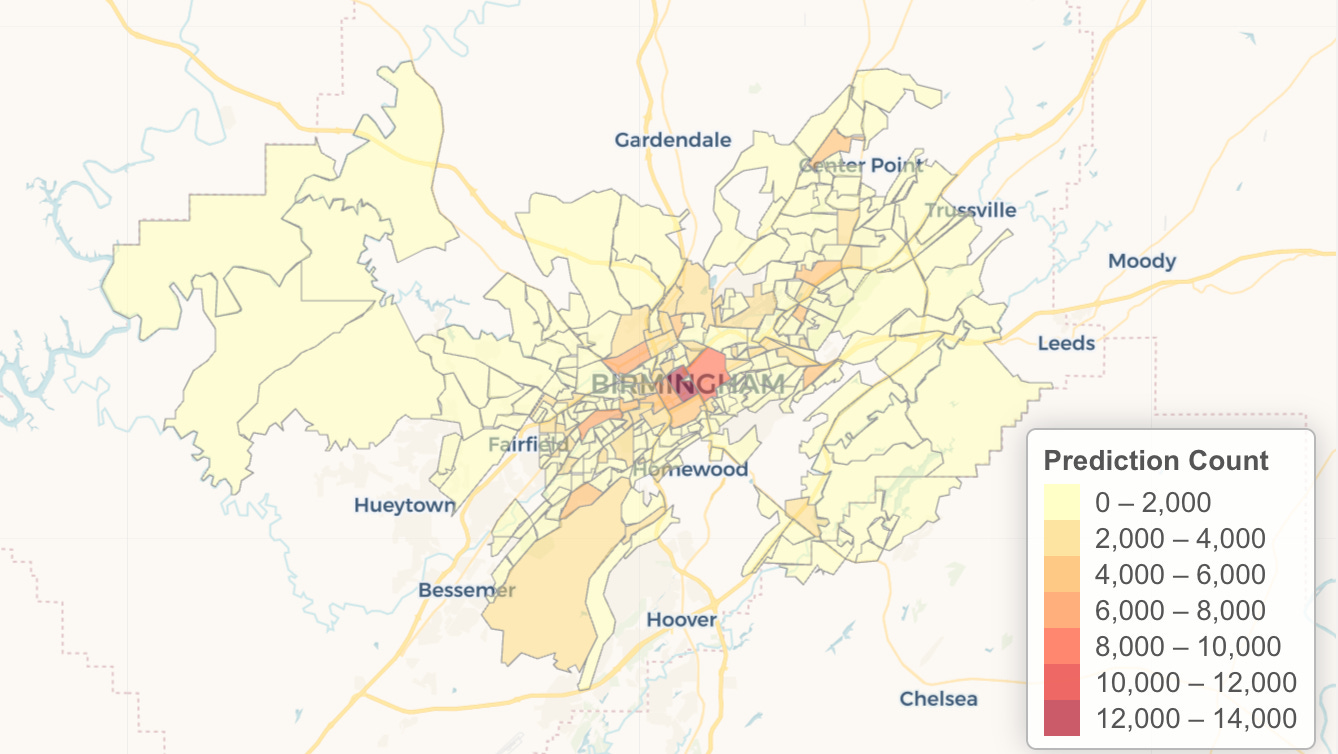
Totally. I almost wonder, like, where is the demand for this kind of software? It doesn't sound like it's necessarily coming from the rank and file of the police departments. Who, I guess, is the customer here, really?
Well. I think a lot of this kind of comes back to the whole kind of CompStat era, which started in the NYPD in the ‘90s. A lot of that is using a lot of data to map crime locations. I think a really important, and I think maybe underrated, element of that entire movement is accountability. It gives the police chiefs this ability to then take their captains and other leadership to say, "Hey, you're in charge of this division, or you're in charge of this area. How come there are so many muggings right here? What are you going to do about it to stop this from happening in the future?" From my conversations with people in the field, that was a pretty fundamental shift in how policing was conceived.
This whole predictive policing model is taking that to the next step of saying, "What can we do to be proactive about preventing crime?" Yes, there are a lot of things you could do to be proactive about preventing crime. But a lot of those things are like giving people social services and getting people jobs and doing all of these gigantic social engineering and social services things. And you're a police chief in a small or medium-size city, you do not have the budget to do all of those things and it's probably not in your mission.
But you can spend $20,000 to $30,000 a year on this system that will allow you to say, "Hey, I'm being proactive," which I think is at least part of the reason that this stuff is happening. At the same time, I don't know, like at least off the top, it's probably for the kind of techier people in law enforcement. It's probably kind of a cool thing to be like, "Hey, there's this computer system that can give me secret insight into how to do this better. Let's give it a shot."
Got it. The story's at The Markup. It's called, "Crime Prediction Software Promised to Be Free of Biases. New Data Shows It Perpetuates Them." You guys also had a really wonderful post explaining exactly how you pulled this off and it is on GitHub. Just to wrap it up, where can folks find you and where can folks find the work?
Surya Mattu: You can find us on Twitter. Mine is @suryamattu. TheMarkup.org is where we publish all our work. I'll plug one more thing, which is that, if you're interested in the data and want to see what it looked like for different cities, if you go to the bottom, we've actually published all those data sheets Aaron mentioned, with maps to show what these predictions actually look like for the 38 different jurisdictions. So definitely play around with that if you're interested in the data.
Aaron Sankin: I also am published at TheMarkup.org. You can find me on Twitter @ASankin. I do want to plug that this story was published in partnership with the technology news site Gizmodo and you can also read it and additional materials on their site as well.
If you have anything you’d like to see in this Sunday special, shoot me an email. Comment below! Thanks for reading, and thanks so much for supporting Numlock.
Thank you so much for becoming a paid subscriber!
Send links to me on Twitter at @WaltHickey or email me with numbers, tips, or feedback at walt@numlock.news.









Numlock Sunday: Surya Mattu and Aaron Sankin on the perils of crime prediction algorithms