

Numlock Sunday: Karen Hao on how to train your AI
Numlock Sunday: Karen Hao on how to train your AI
By Walt Hickey
Welcome to the Numlock Sunday edition. Each week, I'll sit down with an author or a writer behind one of the stories covered in a previous weekday edition for a casual conversation about what they wrote.
This week, I spoke to Karen Hao who a few weeks ago wrote Training a single AI model can emit as much carbon as five cars in their lifetimes in MIT Technology review. Here's what I wrote about it:
University of Massachusetts, Amherst researchers looked at the total computational costs of training several natural language processing AI models, and the reality is that making AI has some significant environmental costs. Extrapolating from measured power requirements and the training hours listed in the papers introducing four AI models — Transformer, ELMo, BERT, and GPT-2 — the researchers estimated how much energy was needed to complete the process of training the models, and, based on the average energy mix in the U.S., how much CO2 was generated to birth the bots. The process of building and testing a publication-worthy model — a process that required training 4,789 models over a 6 month period — would emit an estimated 78,000 pounds of CO2.
I really love Karen’s work, and our conversation covered so much ground that this interview will be split over the next two weeks. This week, everything you need to know about what AI actually is these days, where you can spot it in the wild and just how much energy training it consumes. Next Sunday, we’ll talk about the fundamental ambitions of AI, what’s most surprising in the field, and the story behind why we have deepfakes now.
Karen can be found on Twitter and she has a great newsletter about AI called The Algorithm that, if your interest is piqued here, you should totally check out.
This interview has been condensed and edited.
Walt Hickey: How does someone train a machine learning algorithm?
Karen Hao: AI is a pretty vast field, but as a consumer in your day-to-day, you're probably just engaging with the category of AI called "machine learning." It's a subset and it's specifically statistical methods that are really good at finding patterns in large quantities of data. There are other kinds of AI, but it doesn't really often get used in consumer products.
Machine learning algorithms, you would find those in your Facebook Newsfeed, Google search rankings, all of that. The order in which you see content is determined based on machine learning algorithms. You would also come across them in Netflix recommendations, Spotify recommendations, or YouTube recommendations.
When I'm covering the space, because I'm at Tech Review, I have a pretty research bent. So I'm looking at what are the cutting edge things that are coming out of labs, and some of the big topics in labs recently have been reinforcement learning, which is an even smaller subcategory of machine learning. There's an AI big umbrella, under that is machine learning, under that is reinforcement learning. That is a technique that Deep Mind used to create AlphaGo and have AlphaGo beat the world's best human Go player. When that happened, that sort of created this whole excitement in the research community about this technique.
It's modeled after how we train animals, sort of. You have the carrot and the stick, the carrot that incentivizes good behavior, the stick that deincentivizes bad behavior. Essentially reinforcement learning is like that, where you get an algorithm to try out all these things randomly. Then when it starts doing things that are toward the goal that you want it to reach, you give it lots of rewards. If it starts moving away from the goal that you want to reach, you take points away from it essentially.
Another thing that is popping up a lot is generative adversarial networks, and that's the algorithm behind Deepfakes. Those are images that are completely synthesized and falsified from AI's "imagination." It's a lot of work to understanding how generative adversarial networks work. There's research applying it to different fields, and also lots of thinking around like how do we prevent it from being abused and causing political cacophony.
Generally speaking, when you "train a model," right, a lot of what you're doing is just running a server in a warehouse somewhere? Even setting aside the cool math of it and the core research of it, I love this story that you wrote about the climate change impacts because it really, it does equate computational power, which is hard to place to somebody running a generator.
The concrete process of training is you have a giant dataset, which might be in an Excel spreadsheet you might imagine, but millions of rows of data, and then you are pumping it through this algorithm. In most cases, from a researcher's perspective, you're just interacting with the cloud, that nebulous "cloud" where you're buying computational resources on the server side. It is like a server somewhere in a warehouse, these computers all turn on when you put in your request to say "I want to train this machine learning model" and all those start whirring, and it's essentially putting in the grunt work of actually training the model.
The backstory behind that story is that when I started covering this, this was kind of in the back of my mind for a long time. I immediately saw a parallel with this and bitcoin mining, where bitcoin mining got the energy story around that is a bit more obvious because the actual computers are in the room with the miners. Whereas with AI, you're probably thousands of miles away from the server that you're actually using. You buy the space from the cloud. But to me, I thought there's probably the scale at which some of this training happens, it's probably nearing the scale of energy intensity for bitcoin mining.
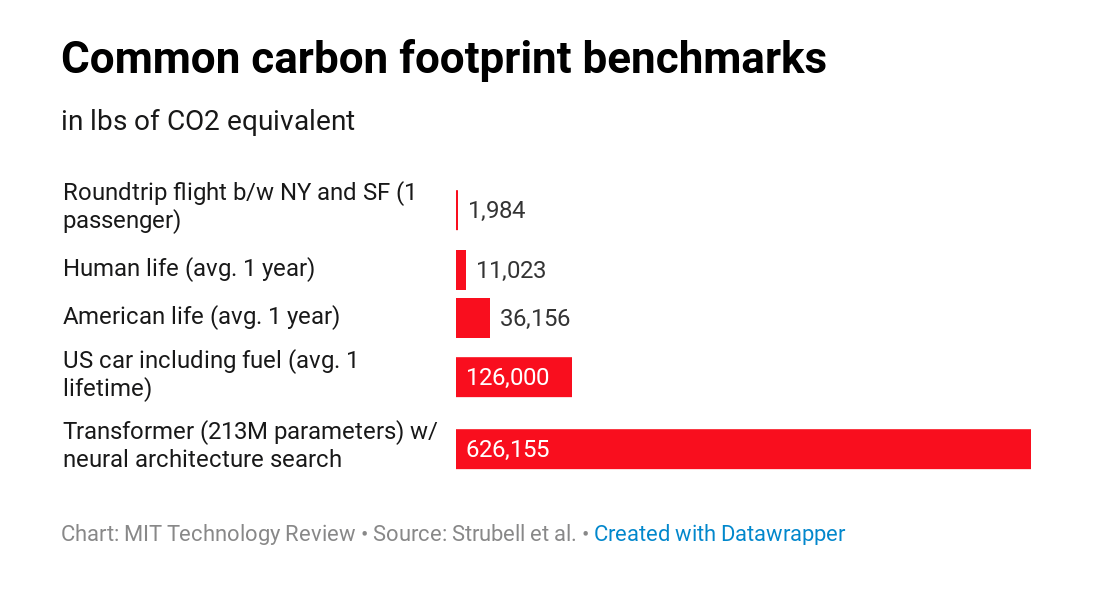
I was kind of just waiting for a paper that would quantify this, and essentially the paper came out. I found it through one of my friends who's an AI researcher at MIT. I was having lunch with her and I was just talking to her about how I was like waiting for this thing to happen because at some point, there would be like a moment of reckoning where all of these really big breakthroughs that have been happening in the research phase have just really been brute force breakthroughs where it's just throwing more training data at ever larger models, and at some point there has to be a point when someone takes a step back and says, "Wait, but what about the energy cost of it?" And she was like, "There's actually a paper that just came out."
Oh my god.
"I just saw a tweet about it like two days ago." Then when I reached out to the researcher, they actually hadn't even released a pre-print of it yet. So I just hounded the researcher to give it to me as soon as possible so that I could write the story, because I thought it was a really important one.
This isn't every time that I get a CAPTCHA and select a stoplight. This is at the beginning when they're creating these larger things, but the calibration happens?
One thing that I suppose is my own critique of my piece is that I think I could have made a little clearer the distinction between training and developing AI models in the research world versus just your everyday Facebook recommendation to order the content in your news feed.
Let's start with industry: in the industry world, when you're applying AI, the models that you're making are probably a lot smaller, because it's expensive because you're buying the server space or you're paying for the electricity bill. Generally the things that you're doing are less sophisticated because the type of machine learning that people perform in a business is not as advanced as what's actually happening in a lab. The scale of that is probably significantly smaller.
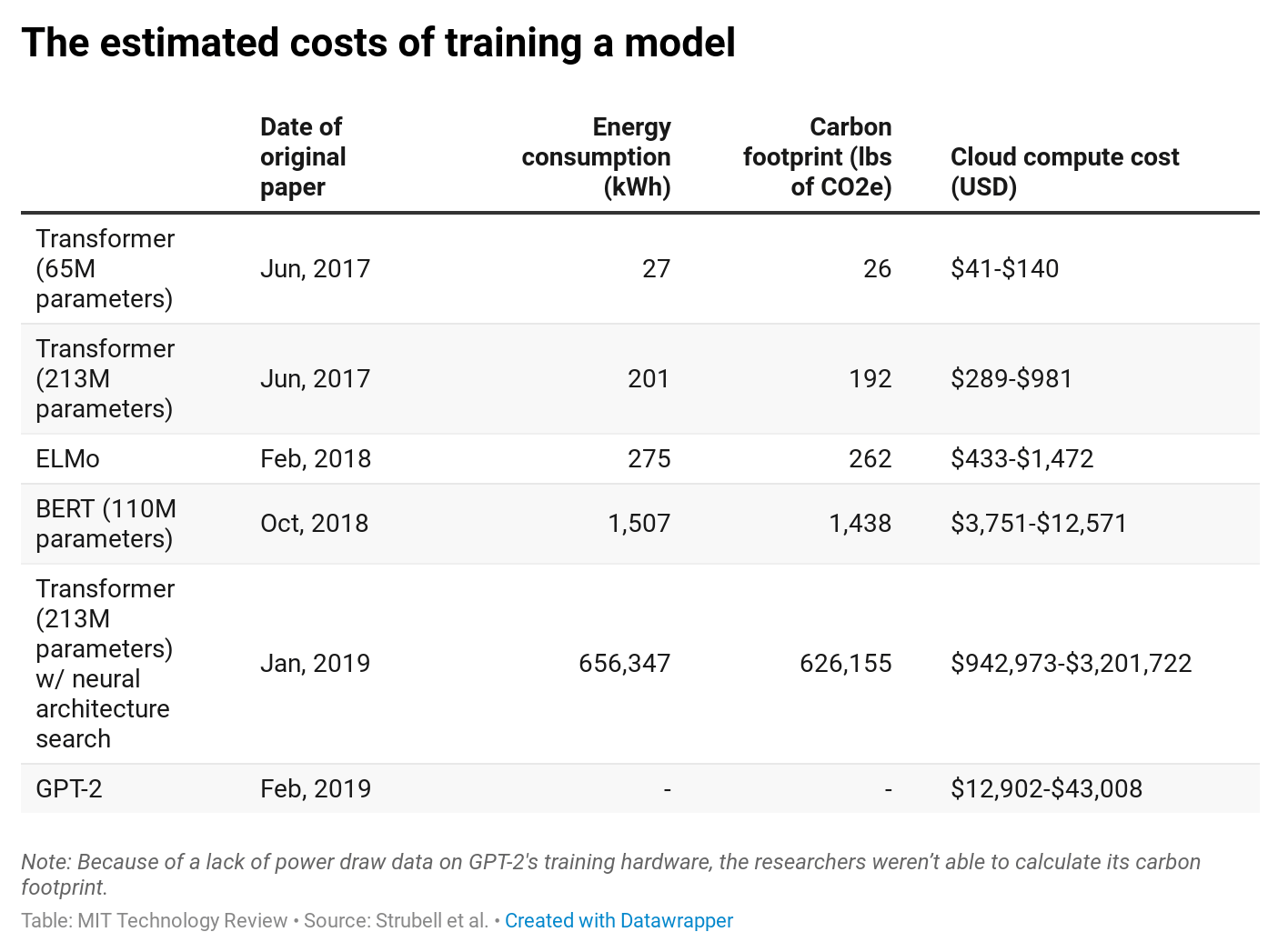
But I would say that it's still something that we should be taking note of, because when you're developing the model before you deploy it, that's like many, many iterations of training. I was very briefly a data scientist at Quartz, and I was building and developing a machine learning model there.
That process of just getting my data and then iterating on the actual model, that can often be like a weeks on process where you're just trying different types of data, you're trying different algorithms, and you're running the thing over and over and over and over and over again until you get the result that you want essentially.
That cumulative process can still be pretty energy intensive, but in the research world it's even exponentially more energy intensive because people are really at the bleeding edge and trying to really push algorithms to do what they haven't done before. In the research world, there's these perverse incentives where essentially you want to try and break a previous benchmark, and you might throw as many computational resources possible just for that benchmark so that you can write a paper about it and you can get attention. The amount of data that people use and the size of the models that people end up building can get really insane.
OpenAI, when they made the news about their natural language model GPT-2, the one that was spinning out fake news articles? The size of that model, to get a model that can actually say somewhat cohesive sentences is pretty insane. With the piece, I really wanted to hammer home there are these weird perverse incentives at play and that there really should be more investment into energy optimization and energy efficient machine learning.
Privatized gains but socialized costs and whatnot, it was interesting because we don't think of our computers as really materially contributing to energy use but in this case it's just really unambiguous.
The rest of the interview runs next Sunday! Karen is at the MIT Technology Review's The Algorithm, and @_karenhao.
If you have anything you’d like to see in this Sunday special, shoot me an email. Comment below! Thanks for reading, and thanks so much for supporting Numlock.
Thank you so much for becoming a paid subscriber!
Send links to me on Twitter at @WaltHickey or email me with numbers, tips, or feedback at walt@numlock.news.
